El open source no falla por el código
Escrito por Ulises Gascón
Nov 24, 2025 — 8 min readEl open source rara vez colapsa en un único momento dramático. Se va erosionando. En silencio. Empiezas a notarlo cuando las releases se estancan, cuando las incidencias se acumulan sin respuesta, cuando ves los mismos dos nombres una y otra vez en el historial de commits. Eso es exactamente lo que pasó con Express y Lodash, dos de los proyectos JavaScript más utilizados del mundo, dos pilares fundamentales del ecosistema Node.js y de la web moderna. Y durante un tiempo, ambos estuvieron mucho más cerca de la irrelevancia o de autodestruirse por agotamiento de lo que la mayoría imagina.
Este artículo parte de mi charla What Comes After Chaos? Lessons from Reviving Express and Reimagining Lodash. Si prefieres el formato vídeo, puedes verla aquí.
Express y Lodash han tocado una parte enorme de la web moderna, apareciendo directa o indirectamente en millones de aplicaciones Node.js y sitios en producción. No porque estuvieran de moda, sino porque estaban en todas partes. Express mueve en silencio millones de servidores, repartidos en decenas de repositorios y decenas de miles de millones de descargas anuales. Lodash vive dentro de aplicaciones en producción, herramientas de build y frameworks con miles de millones de instalaciones y dependencias semanales. Esto no es “un proyecto popular”. Esto es infraestructura.


Y, aun así, la escala no te protege del desgaste. A veces incluso lo acelera.
Cuando la columna vertebral empieza a resquebrajarse
Antes del giro, Express mostraba todos los síntomas de un proyecto que había crecido más rápido que su propia estructura. Decisiones arquitectónicas muy profundas tomadas en los inicios de Node.js se estaban convirtiendo en una carga para el rendimiento y el mantenimiento. Uso de monkey patching, compatibilidad con versiones de Node que nadie debería seguir ejecutando y una batería de tests demasiado inestable como para integrarse en los sistemas de Node. Express 5 llevaba casi una década estando “casi listo”. Mientras tanto, el bus factor práctico rondaba el uno, la gobernanza era como mínimo informal y el backlog de issues y pull requests no dejaba de crecer.

Lodash tenía otro tipo de problema. Durante años, unas pocas personas cargaron con un peso descomunal, y el problema nunca fue su compromiso, sino la estructura que había a su alrededor. A todo esto se sumaban cientos de paquetes derivados y un sistema de integración continua fragmentado que hacía que cualquier avance fuese más lento y más arriesgado de lo que debería. La comunidad pedía Lodash 5 mientras el proyecto aún intentaba sobrevivir a Lodash 4 sin colapsar bajo su propio peso operativo.

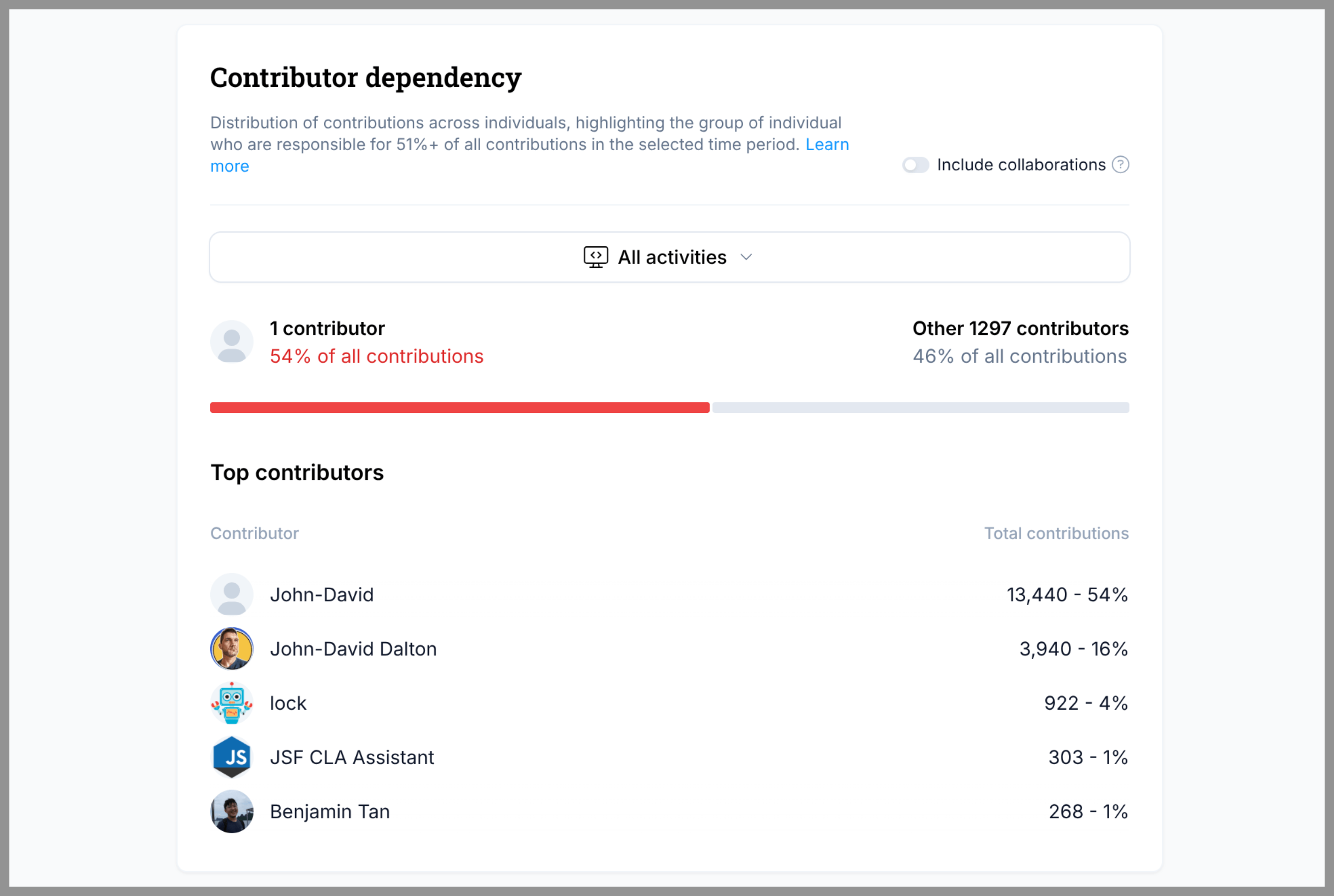
Este suele ser el punto en el que la visión idealizada del open source se encuentra con la realidad. A esta escala, el burnout no es teórico. Se vuelve visible y medible en patrones de contribución, tiempos de respuesta y disponibilidad de mantenedores. Se veía en los gráficos de commits, en los tiempos de respuesta, en el hecho de que dos personas sostuvieran más de la mitad de Express durante años. Y también en estudios más amplios que muestran lo cerca que están muchos maintainers de abandonar.
Lo importante no es que las cosas estuvieran rotas. Lo importante es que nadie tenía una forma sostenible de arreglarlas.
El caos es organizativo antes que técnico
Nos gusta pensar que el software colapsa por culpa del código. No es así. El código se puede reescribir. Los sistemas colapsan cuando no existe una estructura que permita tomar decisiones, gestionar conflictos y repartir el poder.
El primer cambio real en Express no fue un commit. Fue la gobernanza. Un Technical Committee real. Roles definidos como repository captains y committers. Procesos transparentes. Grupos de trabajo con responsabilidad clara en lugar de buena voluntad difusa. La seguridad se trató como un sistema, no como una checklist: threat models, auditorías externas, planes de respuesta a incidentes y un equipo dedicado de triage. Las releases dejaron de ser deseos. Pasaron a ser planificadas, mantenidas y comunicadas.

Esto importó porque reconstruyó algo más valioso que el código: la confianza. No solo de los usuarios, sino también de contribuidores, empresas y del ecosistema. Express volvió al sistema de testing de Node.js, obtuvo estatus de Impact Project dentro de la OpenJS Foundation y finalmente lanzó Express 5 con una hoja de ruta más allá.
Lodash está recorriendo un camino similar, pero con sus propias limitaciones y cultura. Pasando de un modelo BDFL a un Technical Steering Committee. Deprecando gran parte del ecosistema de variantes para recuperar control sobre la complejidad. Reconstruyendo su CI para que las releases dejen de ser gestas heroicas. Centrados en la estabilidad, la seguridad y una modernización progresiva, en lugar de priorizar nuevas funcionalidades.

Este es un trabajo más lento. Menos visible. Menos excitante en redes sociales. Pero así es como se transforma una infraestructura madura.
No todo lo que parece drama lo es
Cuando proyectos del tamaño de Express o Lodash hacen cambios, internet tiende a convertirlo todo en crisis o escándalo. Oleadas de pull requests irrelevantes o de baja calidad. Artículos de “¿está muerto este proyecto?”. Hilos sobre abandonar librerías por alternativas más ligeras. Gran parte de ese ruido pierde el punto de fondo. Los ecosistemas maduros siempre generan fricción porque tienen gravedad. Pero no todo momento de tensión es un fracaso. A veces es simplemente el coste de pasar de lo informal a lo intencional.
No importa si existe conflicto. Importa si el proyecto tiene estructuras para gestionarlo sin quemar a la gente.
Lo que realmente sobrevive después del caos
Hoy Express no es solo un framework. Es una organización. Lodash ya no es solo una librería de utilidades. Es un proyecto aprendiendo a escalar su gobernanza al mismo nivel que su código. El trabajo invisible detrás de este cambio suele ignorarse: mentorizar nuevos mantenedores, repartir decisiones, documentar procesos, crear espacios seguros para el desacuerdo y tratar la seguridad y la sostenibilidad como algo central, no como un añadido.


El open source no sobrevive solo a base de pull requests. Sobrevive gracias a estructura, a propiedad compartida y a la decisión incómoda de dejar de ser heroico para empezar a ser aburrido.
Y esto es lo que viene después del caos. No perfección. No un final feliz. Solo transformación. Lenta, deliberada, a veces frustrante y absolutamente necesaria. Si alguna vez has escrito npm install express o npm install lodash, ya has sido parte de esta historia, lo supieras o no.
También hay que decir la parte incómoda en voz alta. No arreglamos esto porque apareciera un montón mágico de dinero. El apoyo importa, y iniciativas como el Sovereign Tech Fund han marcado una diferencia real haciendo posible este trabajo. Pero la financiación por sí sola no resuelve problemas estructurales. En la mayoría de los casos, los recursos siguen sin ser suficientes. Lo que más peso tuvo fue la estructura, la gobernanza y la propiedad compartida. Y aunque los proyectos sean “rescatados” y celebrados, su sostenibilidad a largo plazo sigue siendo frágil. La recuperación es una fase, no una conclusión. Requiere mantenimiento constante.
Lo que viene después del caos… es simplemente transformación.